由於記憶體是一種不可壓縮資源,所以 usage 超過 limits 就會出現 OOMKill,由於 OOMKills 是會終止 Pod,所以配置 pod 資源的時候,有一種常見的配置方式,就是先讓應用程式上線跑跑看,這是我們會,運行一陣子來收集真實世界的數據,然後根據這些數據加上 resources.limits。
這樣配置 limits.memory 緩解 OOMKills 的問題之後,我們通常也會一同設定 limits.cpu,但是 CPU 是可壓縮資源,所以我們經常忽視 CPU。接下來會從宏觀的角度以及微觀的角度分析 limits.cpu
跟 resources.requests 一樣,resources.limits 最終會落地到 cgroup, 以 cgroup v2 為例,resoures.limits.cpu 會變成 cpu.max,cpu.max 會在 Process 使用完 CFS Quota 之後發動 CPU Throttling,中斷 Process。
這邊值得注意的是:並不是 Usage 在 Limits 之下就沒事,只要設定 cpu.limits CPU Throttling
就有可能發動,所以建議是:
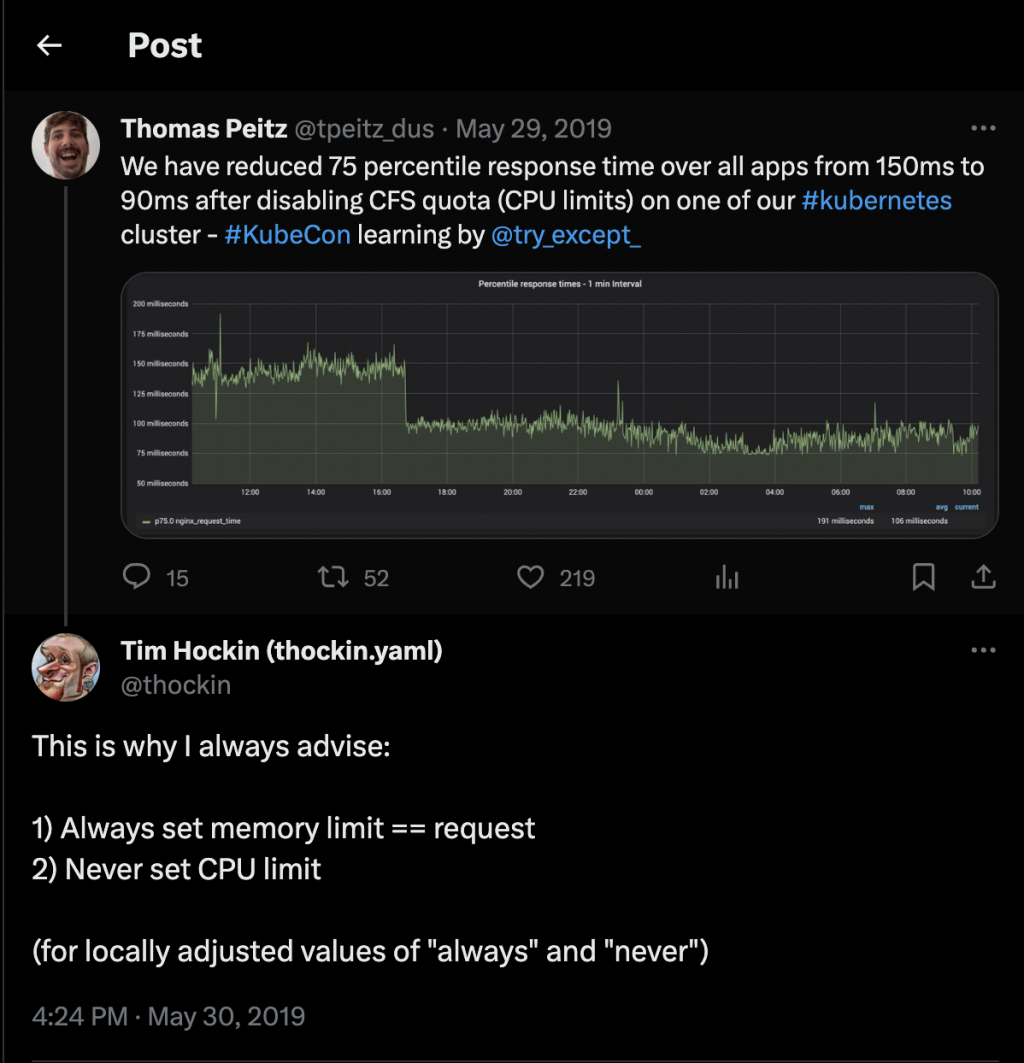
為了理解這個問題,我們可以從 Metrics 來觀察 CPU Throttling 的狀況。
cAdvisor 會收集三個跟 CPU Throttling 的指標
container_cpu_cfs_throttled_seconds_total
container_cpu_cfs_periods_total
container_cpu_cfs_throttled_periods_total
第一個是 Throttled 的總秒數,由於會和 Thread 數量有關係,所以參考價值有限。
container_cpu_cfs_periods_total 就是走了多少 CFS Periods, container_cpu_cfs_throttled_periods_total 是有多少 Throttled CFS Periods。
所以我們把 container_cpu_cfs_periods_total / container_cpu_cfs_throttled_periods_total就可以得到現在有多少比例的 Throttled CFS Periods。
Benchmarking
在測試環境用設定 resources.limits.cpu = resources.requests.cpu,藉此觀察 Throttled CFS Periods 的比例。
Multi-tenant environments
多租戶環境下,你需要限制租戶 Pod 不會競爭其他資源,通常多租戶環境下我們會用 ResourceQuota 限制所有 Container 都有 requests 以及 limits
這個是比較深入的誤解,CPU Throttling 有可能造成 OOMKilled 是因為現在 GC 類型的語言都是靠者 Thread GC,如果 GC Thread 一直被 CPU Throttling 影響,這樣的話確實有可能造成 OOMKilled。
cgroup 坑太大了啦,我現在才只寫到一半,這樣後面有些想寫的會來不及寫完,要先止損了嗎?

